As the first post in a series on the topic of Design Systems, this post will attempt to cover some of the basics of Computational Design — a foundation for future posts to build on.
Computational Design has found its way into mainstream practice in the AEC industry. Within the last decade, the field has gone from being a mostly academic interest pursued outside of academia — by dedicated teams of specialists inside larger innovative companies and small, research-focused firms — to a practice which can now be found in most large organisations. Today the term is commonly recognised, or at least it’s no longer completely foreign to most. But there is still some unclarity about what it actually is and how to use it. In this post, I will try to explain the what, why and how of Computational Design, as well as offer a definition of it.
The What
Computational Design is often confused, or used interchangeably, with terms like parametric design, VDC (virtual design and construction), visual programming, generative design, algorithmic design, emergent design, computational morphogenesis and others.
Without attempting to define all of these terms, I should say that “parametric design” isn’t actually design at all, but rather parametric modelling. Parametric modelling is used in Computational Design, but it is not the design activity itself. A longer discussion of the relationship between these two terms can be found in this post by Francesco Cingolani, which can be summed up here with the following meme:

Modelling is of course a key part of Computational Design, and it is worth clarifying the distinction of between different modelling approaches before combining this with a design approach.
Modelling terminology
David Stasiuk’s paper “Design Modelling Terminology” does an excellent job of clarifying the terms procedural, parametric, computational and generative modelling. Here’s a summary of the terminology:
Procedural modelling
Procedural modelling is the superset of the other modelling types. It is the use of an explicit instruction set to produce a model outcome. Instead of modelling directly with a pen or mouse-clicks, the model outcome is directed by manipulating the instruction set, i.e. an algorithm. There are 3 types of procedural modelling:
Parametric modelling
In his PhD thesis “Modelled on Software Engineering: Flexible Parametric Models in the Practice of Architecture,” Daniel Davis provides the following succinct definition: “parametric modelling is a set of equations that express a geometric model as explicit functions of a number of parameters.” The output can be more general information, it is not limited to geometry. There are three components to this: parameters, algorithm and outcomes (or input-process-output). Some key usages of parametric modelling are exploration and rapid versioning by means of varying input parameters.
Computational modelling
According to the physicist and philosopher Heinz von Foerster, “computing…literally means to reflect, to contemplate (putare) things in concert (com‐), without any explicit reference to numerical quantities.” Computation then reflects “any operation, not necessarily numerical, that transforms, modifies, re‐arranges, or orders observed physical [or symbolic] entities…”
It is important to distinguish between the terms computation and computerisation. The former refers to the process of deducing results from values — increasing the amount and specificity of information. The latter refers to the simple compilation or association of given values — no additional information, other than what is supplied, is produced. A computational model embeds all of the characteristics of the parametric model, but the difference is that the computational model computes new information about the design system. And while the parametric model uses static parameters during model execution, the computational model is able to use a parameterisation that is dynamic and responsive, such as a form-finding model.
So, computational design must be considered an information-producing activity, not simply a translational representation.
Generative modelling
Philip Galanter, an artist and researcher focused on “generative art,” offers this definition: “Generative art refers to any art practice where the artist uses a system, such as a set of natural language rules, a computer program, a machine or other procedural invention, which is set into motion with some degree of autonomy contributing to or resulting in a completed work of art.” Using this definition, what can be considered generative design is fairly open; the only requirement is that it needs to have some degree of algorithmic autonomy. Other definitions of the term offer more specificity. For example, generative systems can be defined according to their ability to deploy algorithmic transformations and “re‐use embedded sub‐systems,” specifically incremental morphogenesis. And generative processes have also been considered “an active space of progressive formation and mutation” in the digital design process. Bringing this together, David Stasiuk offers the following definition:
“A generative model will be understood as one that not only meets all of the criteria for being a computational model, but which during a single execution instance additionally incorporates a capacity for unfixed topological relationships between model elements, and/or is actualized through the step‐wise accretion of new model elements that are morphogenically recursive, with incremental stages of formation dependent upon preceding steps enacted during the model execution.”
David Stasiuk
I like this well-considered definition of generative modelling and consider it accurate. However, the term is not used consistently. If you search for “Generative Design” the first result will likely not be in line with the above understanding of “generative modelling.” Autodesk uses the following descriptions: “Generative design is a design exploration process” and “[generative design is] a goal-driven approach to design that uses automation to give […] more informed design decisions”. The term used here is generative design, not generative modelling, but the usage is not in line with the definition provided above. This definition is actually closer to computational modelling than to generative. But “batch processing the solution-space of a parametric model” is of course not as catchy a tag line as “design exploration.” The term is disputed, and looking at the edits of the Wikipedia page for “generative design,” we can see that the term has changed meaning over time.

Computational Design
Clarifying these modelling terms, and the differences between them, is important for trying to understand what computational design is. From the above, it should be clear that it is an information-producing activity. Computational design is really focused on the process that arrives at the outcome, rather than being singularly focused on the outcome itself.
Let’s see if we can put together a definition of computational design by looking at the individual words in the term: computation and design.
Computation is the calculation of a well-defined model expressed as an algorithm.
Calculation is a process that transforms inputs into outputs (results)
a model is a representation of a system.
A system is a set of interdependent parts forming a more complex whole, described by its structure, purpose, boundary and influenced by its environment.
Well-defined entails that there is a unique interpretation; no ambiguity.
Algorithm is a set of instructions that, when executed, steps through a finite number of successive, well-defined states to produce an output.
Design has been defined in many ways by various people. To be clear, we are interested in design (the process), not Design (the product of that process). I am particularly fond of Charles Eames’ rather broad understanding of the design activity:
Designing is creating a plan for arranging elements to accomplish a particular purpose.
Charles Eames
The particular purpose is the goal, result or (potential) solution to a problem (this also suggests that design is a problem-based activity).
Arranging elements is the construction of a model representing a system.
A plan is a set of instructions for attaining a given objective (or organising steps, timing and resources), and planning is the organisational process of creating a plan.
With this in mind, Computational Design can be defined as follows:
The act of formulating (or defining) the interdependent parts of an un-ambiguous system (model) and the instruction set (algorithm) that transforms this system into a desired state (objective).

The full story of computational design, and its history, are beyond the scope of this post. If you are interested in learning more about it, I recommend reading Computational Design Thinking by Sean Alquist and Achim Menges, which also contains excerpts from some of the most referenced books on this topic.
The Why
So why would one choose to go through the extra effort required by Computational Design? Why not simply create a static geometric model representing a desired outcome? Why not just do it manually?
First: Because things change.
It is unlikely, if not impossible, for you to know all of the possible issues that will influence a design, and to resolve all of these issues in one go, at the very beginning of the design process. The design will inevitably change, and having a representation of a system that is adaptive to change allows the design process to continue moving forward, rather than halting and having to restart.
It is adaptive.
Second: Because it lets you change things.
With an adaptive system that can quickly, and sometimes instantly, adapt to change, there is opportunity for design exploration. That is, rather than adapting to externally imposed changes, you intentionally impose changes to create variations of the design. This design exploration process allows more options to be evaluated. And evaluating more options increases the chance of finding better-performing options in the design process.
It allows for greater design exploration.
Third: Because it has a greater capacity for data.
Evaluating a design requires data output from the system, and Computational Design has a greater capacity for data than any manual approach. And it isn’t just the system output that allows for more data, but the input does as well. This means you can feed the model data that you want it to take into consideration when you run it. This could be data on the physical context of a building, such as climate data which allows the model to consider temperature, daylight and other environmental factors. This could also be data generated by the model itself, such as the structural performance of the building. The range of data that can be incorporated into this design process is almost limitless and can move design development towards a data-driven process.
It can provide more information about design performance.
Fourth: Because it has a greater capacity for complexity.
Since the early days of their use in building design, parametric models have been employed to create complex geometries. While it is not the purpose of Computational Design to create complex geometries, it still has the capacity to do it. That is, buildings with complex shapes are more feasible with design. At least to model, analyse and evaluate. The physical construction itself is still somewhat limited in terms of what level of complexity is feasible. It should be noted that complexity has varied meanings, and the meaning used here is closest to that of algorithmic complexity, where the level of complexity has to do with the length of the description. So, Computational Design not only has a greater capacity for geometric complexity in a design, but also greater capacity for any information embedded in that design and, more importantly, the ability to manage this information.
It can manage complexity.
Fifth: Re-use.
Encoding the logic of a design solution in an algorithm allows you to reuse the solution the next time a similar problem is encountered. When it comes to design, the problems are never exactly the same. So, this does require some generalisation of the solution. However, a solution can become too generalised to be useful for a specific design problem. So, a balance needs to be found between being specific enough to solve the current problem and being general enough to be useful for solving similar problems. This also relates to the size of the design problem: you cannot define an entire building as a single problem with a corresponding solution in algorithmic form. But there are some smaller design problems that appear often across different building projects.
It allows solutions to be re-deployed without (much) additional effort.
Sixth: Automation.
This is implied above, so it might already be clear. But it deserves to be made explicit, as it is possibly the clearest benefit of Computational Design: the automation of monotonous tasks. This speeds up the design iterations, allowing more iterations in the development of the design.
It can automate design tasks.
The How
Solving any problem starts with thinking. Identifying the problem is part of this thinking, and of course solving problems computationally requires computational thinking.
Computational thinking is the thought process involved in defining problems so that their solutions can be represented in a form that can be computed.
Defining the problem is a critical step. A clearly defined problem helps to ensure that the right problem is being solved. This is essential in computational problems because of the additional time needed to produce a initial output.
It is equally important to realise that your understanding of the problem can evolve throughout the design process — design is a wicked problem — so the computational model should be as adaptable as possible.
Also, note that the Computational Design part is most likely only part of the overall design solution, that is, it only solves a sub-problem — you are not using one algorithm to solve all of the problems involved in the design of an entire building. This also means that the computational processes should be able to interact with each other: the massing algorithm interacts with the solar analysis, which interacts with the façade, which interacts with the floor layout, which interacts with the structure, and so on. This is not a simple linear chain of interactions, but more like a complex network of interdependencies. I will go into this in more detail in a future post.
In practice, the work is usually done in text-based scripts such as C# or Python, or in flow-based programming environments like Grasshopper or Dynamo, or a combination of them all. This is not a tutorial, so I won’t go into the practical use of these tools. However, you should know that what they all have in common is that they take an input and process it into a desired output. Your solution should always take this form: input – process – output.

In its essence, Computational Design is about designing processes — processes with discrete sequential steps. I find the best way to approach this is to start with the input and the output before creating the process that transforms the input into the desired output. The input and output are usually easier to get a grasp on: deciding what result you want and what data is available. Doing this also lays out some constraints on the process that turns the input into the output, which aids in the more complex step of defining the process.
Part of this complexity comes from the fact that computers are dumb. They don’t get inferred meaning. So, each step in the process needs to be explicitly defined. Often, people don’t realize just how complex this can be until they get stuck trying to create the process. Imagine trying to write a recipe where it’s not enough to simply say “chop vegetable,” but where you need to describe what this actually means: “Place the vegetable on the flat side of the cutting board. With the sharp side of the knife, cut x millimetres off of the end of the vegetable. Raise the knife. Move the vegetable x millimetres. Repeat until the other end of the vegetable is reached. If a finger is under the knife, then abort.” This “chop vegetable” procedure isn’t even applicable to all vegetables. It might work well for carrots, but it will need to be customised for cutting onions.
What adds to the complexity of defining the process is the fact that the “chop vegetable” procedure is only a small part of the solution. It’s just one step. And it needs to interact with other steps in the process: stir, bake, fry, boil, etc. The desired output isn’t just a chopped vegetable, it’s a delicious meal. An example of these interactions is nicely visualised in the following flowchart recipe for chicken tikka masala:
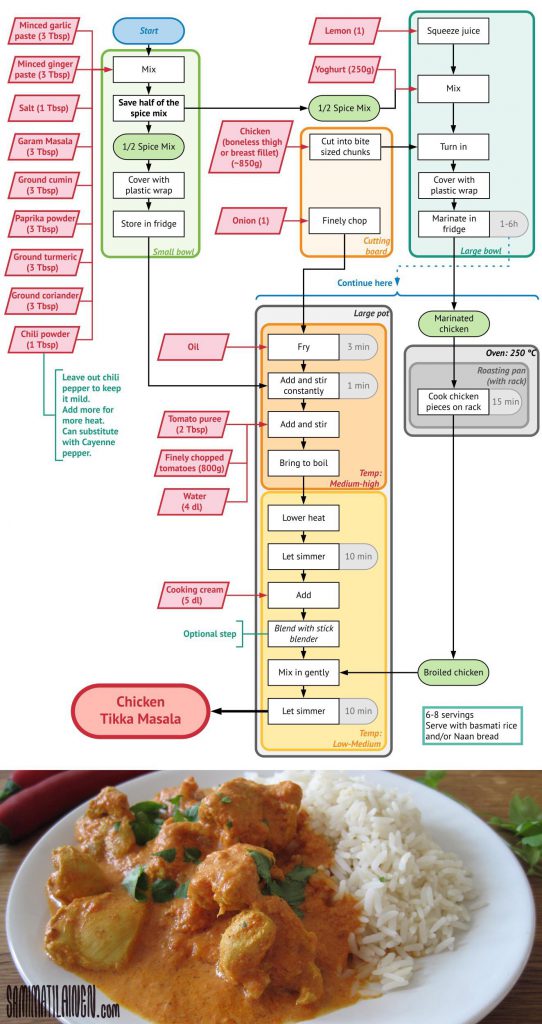
This post does not go into detail on how to practically apply Computational Design. It is not intended to be a how-to guide, but rather a high-level introduction to Computational Design. There are a lot more aspects to consider when implementing Computational Design in an organisation, in a strategy and on projects. More than I can fit into this post. I will follow up on this in a future post on “Implementing Computational Design.”